Multiple-Processor Scheduling
5.5 Multiple-Processor Scheduling
- When multiple processors are available, then the scheduling gets more complicated, because now there is more than one CPU which must be kept busy and in effective use at all times.
- Load sharing revolves around balancing the load between multiple processors.
- Multi-processor systems may be heterogeneous, ( different kinds of CPUs ), or homogenous, ( all the same kind of CPU ). Even in the latter case there may be special scheduling constraints, such as devices which are connected via a private bus to only one of the CPUs. This book will restrict its discussion to homogenous systems.
5.5.1 Approaches to Multiple-Processor Scheduling
- One approach to multi-processor scheduling is asymmetric multiprocessing, in which one processor is the master, controlling all activities and running all kernel code, while the other runs only user code. This approach is relatively simple, as there is no need to share critical system data.
- Another approach is symmetric multiprocessing, SMP, where each processor schedules its own jobs, either from a common ready queue or from separate ready queues for each processor.
- Virtually all modern OSes support SMP, including XP, Win 2000, Solaris, Linux, and Mac OSX.
5.5.2 Processor Affinity
- Processors contain cache memory, which speeds up repeated accesses to the same memory locations.
- If a process were to switch from one processor to another each time it got a time slice, the data in the cache ( for that process ) would have to be invalidated and re-loaded from main memory, thereby obviating the benefit of the cache.
- Therefore SMP systems attempt to keep processes on the same processor, via processor affinity. Soft affinity occurs when the system attempts to keep processes on the same processor but makes no guarantees. Linux and some other OSes support hard affinity, in which a process specifies that it is not to be moved between processors.
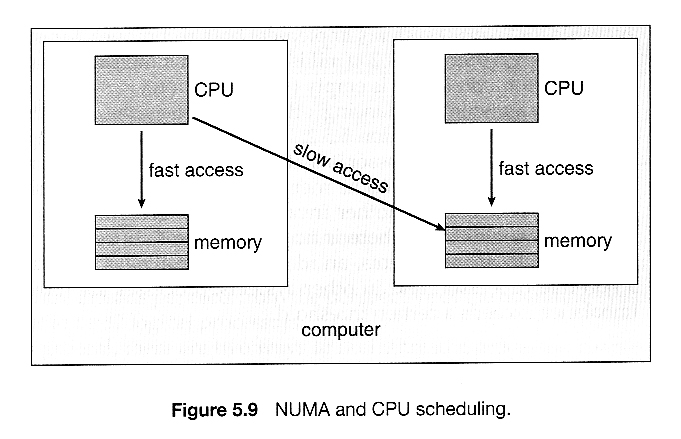
- Main memory architecture can also affect process affinity, if particular CPUs have faster access to memory on the same chip or board than to other memory loaded elsewhere. ( Non-Uniform Memory Access, NUMA. ) As shown below, if a process has an affinity for a particular CPU, then it should preferentially be assigned memory storage in "local" fast access areas.
5.5.3 Load Balancing
- Obviously an important goal in a multiprocessor system is to balance the load between processors, so that one processor won't be sitting idle while another is overloaded.
- Systems using a common ready queue are naturally self-balancing, and do not need any special handling. Most systems, however, maintain separate ready queues for each processor.
- Balancing can be achieved through either push migration or pull migration:
- Push migration involves a separate process that runs periodically, ( e.g. every 200 milliseconds ), and moves processes from heavily loaded processors onto less loaded ones.
- Pull migration involves idle processors taking processes from the ready queues of other processors.
- Push and pull migration are not mutually exclusive.
- Note that moving processes from processor to processor to achieve load balancing works against the principle of processor affinity, and if not carefully managed, the savings gained by balancing the system can be lost in rebuilding caches. One option is to only allow migration when imbalance surpasses a given threshold.
5.5.4 Multicore Processors
- Traditional SMP required multiple CPU chips to run multiple kernel threads concurrently.
- Recent trends are to put multiple CPUs ( cores ) onto a single chip, which appear to the system as multiple processors.
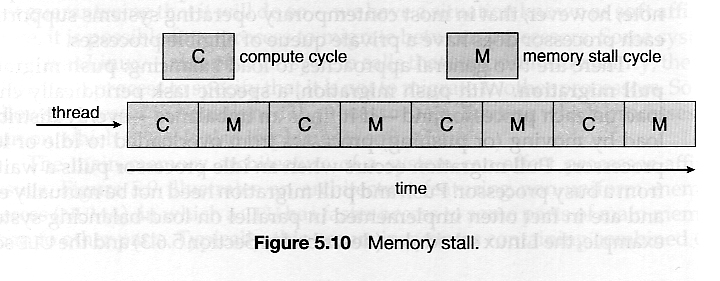
- Compute cycles can be blocked by the time needed to access memory, whenever the needed data is not already present in the cache. ( Cache misses. ) In Figure 5.10, as much as half of the CPU cycles are lost to memory stall.
- By assigning multiple kernel threads to a single processor, memory stall can be avoided ( or reduced ) by running one thread on the processor while the other thread waits for memory.
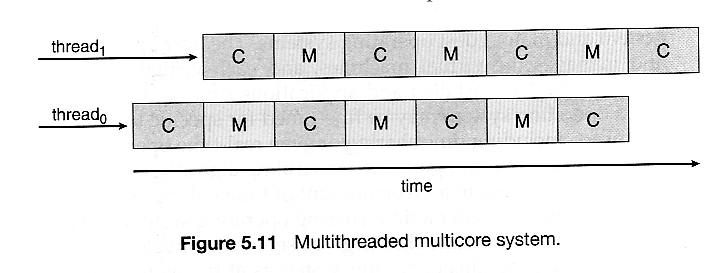
- A dual-threaded dual-core system has four logical processors available to the operating system. The UltraSPARC T1 CPU has 8 cores per chip and 4 hardware threads per core, for a total of 32 logical processors per chip.
- There are two ways to multi-thread a processor:
- Coarse-grained multithreading switches between threads only when one thread blocks, say on a memory read. Context switching is similar to process switching, with considerable overhead.
- Fine-grained multithreading occurs on smaller regular intervals, say on the boundary of instruction cycles. However the architecture is designed to support thread switching, so the overhead is relatively minor.
- Note that for a multi-threaded multi-core system, there are two levels of scheduling, at the kernel level:
- The OS schedules which kernel thread(s) to assign to which logical processors, and when to make context switches using algorithms as described above.
- On a lower level, the hardware schedules logical processors on each physical core using some other algorithm.
- The UltraSPARC T1 uses a simple round-robin method to schedule the 4 logical processors ( kernel threads ) on each physical core.
- The Intel Itanium is a dual-core chip which uses a 7-level priority scheme ( urgency ) to determine which thread to schedule when one of 5 different events occurs.
5.5.5 Virtualization and Scheduling
- Virtualization adds another layer of complexity and scheduling.
- Typically there is one host operating system operating on "real" processor(s) and a number of guest operating systems operating on virtual processors.
- The Host OS creates some number of virtual processors and presents them to the guest OSes as if they were real processors.
- The guest OSes don't realize their processors are virtual, and make scheduling decisions on the assumption of real processors.
- As a result, interactive and especially real-time performance can be severely compromised on guest systems. The time-of-day clock will also frequently be off.