13.2 I/O Hardware
- I/O devices can be roughly categorized as storage, communications, user-interface, and other
- Devices communicate with the computer via signals sent over wires or through the air.
- Devices connect with the computer via ports, e.g. a serial or parallel port.
- A common set of wires connecting multiple devices is termed a bus.
- Buses include rigid protocols for the types of messages that can be sent across the bus and the procedures for resolving contention issues.
- Figure 13.1 below illustrates three of the four bus types commonly found in a modern PC:
- The PCI bus connects high-speed high-bandwidth devices to the memory subsystem ( and the CPU. )
- The expansion bus connects slower low-bandwidth devices, which typically deliver data one character at a time ( with buffering. )
- The SCSI bus connects a number of SCSI devices to a common SCSI controller.
- A daisy-chain bus, ( not shown) is when a string of devices is connected to each other like beads on a chain, and only one of the devices is directly connected to the host.
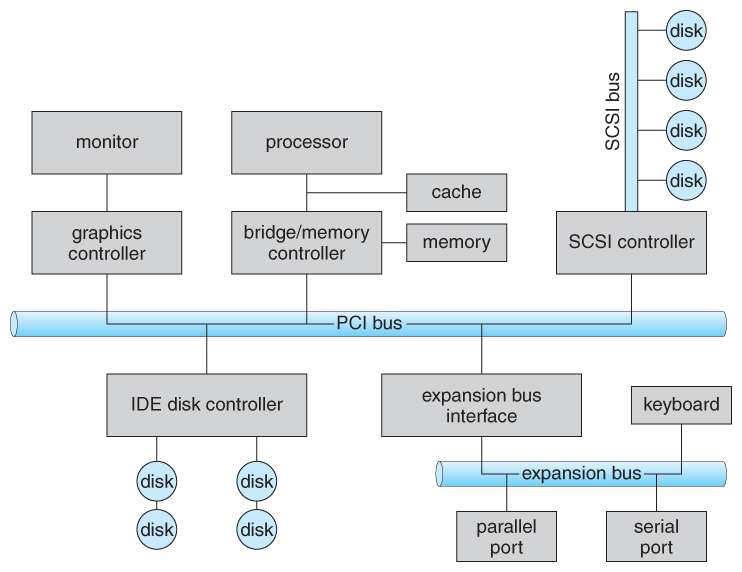
Figure 13.1 - A typical PC bus structure.
- One way of communicating with devices is through registers associated with each port. Registers may be one to four bytes in size, and may typically include ( a subset of ) the following four:
- The data-in register is read by the host to get input from the device.
- The data-out register is written by the host to send output.
- The status register has bits read by the host to ascertain the status of the device, such as idle, ready for input, busy, error, transaction complete, etc.
- The control register has bits written by the host to issue commands or to change settings of the device such as parity checking, word length, or full- versus half-duplex operation.
- Figure 13.2 shows some of the most common I/O port address ranges.
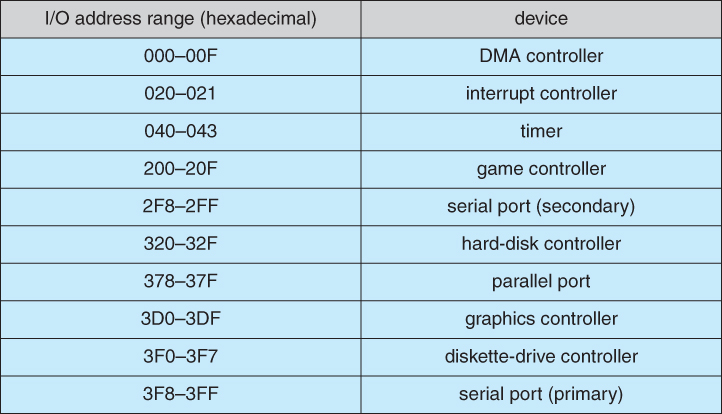
Figure 13.2 - Device I/O port locations on PCs ( partial ).
- Another technique for communicating with devices is memory-mapped I/O.
- In this case a certain portion of the processor's address space is mapped to the device, and communications occur by reading and writing directly to/from those memory areas.
- Memory-mapped I/O is suitable for devices which must move large quantities of data quickly, such as graphics cards.
- Memory-mapped I/O can be used either instead of or more often in combination with traditional registers. For example, graphics cards still use registers for control information such as setting the video mode.
- A potential problem exists with memory-mapped I/O, if a process is allowed to write directly to the address space used by a memory-mapped I/O device.
- ( Note: Memory-mapped I/O is not the same thing as direct memory access, DMA. See section 13.2.3 below. )
13.2.1 Polling
- One simple means of device handshaking involves polling:
- The host repeatedly checks the busy bit on the device until it becomes clear.
- The host writes a byte of data into the data-out register, and sets the write bit in the command register ( in either order. )
- The host sets the command ready bit in the command register to notify the device of the pending command.
- When the device controller sees the command-ready bit set, it first sets the busy bit.
- Then the device controller reads the command register, sees the write bit set, reads the byte of data from the data-out register, and outputs the byte of data.
- The device controller then clears the error bit in the status register, the command-ready bit, and finally clears the busy bit, signaling the completion of the operation.
- Polling can be very fast and efficient, if both the device and the controller are fast and if there is significant data to transfer. It becomes inefficient, however, if the host must wait a long time in the busy loop waiting for the device, or if frequent checks need to be made for data that is infrequently there.
13.2.2 Interrupts
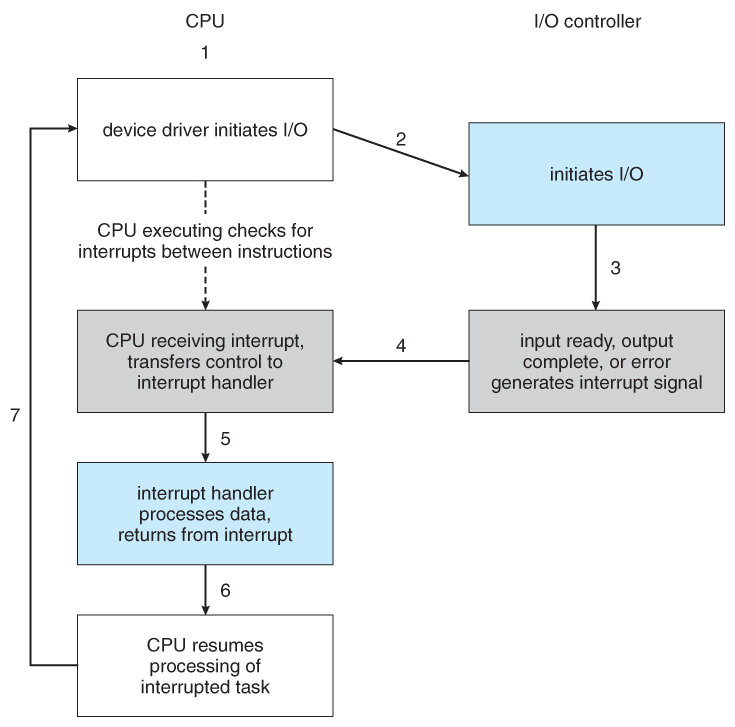
- Interrupts allow devices to notify the CPU when they have data to transfer or when an operation is complete, allowing the CPU to perform other duties when no I/O transfers need its immediate attention.
- The CPU has an interrupt-request line that is sensed after every instruction.
- A device's controller raises an interrupt by asserting a signal on the interrupt request line.
- The CPU then performs a state save, and transfers control to the interrupt handler routine at a fixed address in memory. ( The CPU catches the interrupt and dispatchesthe interrupt handler. )
- The interrupt handler determines the cause of the interrupt, performs the necessary processing, performs a state restore, and executes a return from interrupt instruction to return control to the CPU. ( The interrupt handler clears the interrupt by servicing the device. )
- ( Note that the state restored does not need to be the same state as the one that was saved when the interrupt went off. See below for an example involving time-slicing. )
- Figure 13.3 illustrates the interrupt-driven I/O procedure:
Figure 13.3 - Interrupt-driven I/O cycle.
- The above description is adequate for simple interrupt-driven I/O, but there are three needs in modern computing which complicate the picture:
- The need to defer interrupt handling during critical processing,
- The need to determine which interrupt handler to invoke, without having to poll all devices to see which one needs attention, and
- The need for multi-level interrupts, so the system can differentiate between high- and low-priority interrupts for proper response.
- These issues are handled in modern computer architectures with interrupt-controller hardware.
- Most CPUs now have two interrupt-request lines: One that is non-maskable for critical error conditions and one that is maskable, that the CPU can temporarily ignore during critical processing.
- The interrupt mechanism accepts an address, which is usually one of a small set of numbers for an offset into a table called the interrupt vector. This table ( usually located at physical address zero ? ) holds the addresses of routines prepared to process specific interrupts.
- The number of possible interrupt handlers still exceeds the range of defined interrupt numbers, so multiple handlers can be interrupt chained. Effectively the addresses held in the interrupt vectors are the head pointers for linked-lists of interrupt handlers.
- Figure 13.4 shows the Intel Pentium interrupt vector. Interrupts 0 to 31 are non-maskable and reserved for serious hardware and other errors. Maskable interrupts, including normal device I/O interrupts begin at interrupt 32.
- Modern interrupt hardware also supports interrupt priority levels, allowing systems to mask off only lower-priority interrupts while servicing a high-priority interrupt, or conversely to allow a high-priority signal to interrupt the processing of a low-priority one.
Figure 13.4 - Intel Pentium processor event-vector table.
- At boot time the system determines which devices are present, and loads the appropriate handler addresses into the interrupt table.
- During operation, devices signal errors or the completion of commands via interrupts.
- Exceptions, such as dividing by zero, invalid memory accesses, or attempts to access kernel mode instructions can be signaled via interrupts.
- Time slicing and context switches can also be implemented using the interrupt mechanism.
- The scheduler sets a hardware timer before transferring control over to a user process.
- When the timer raises the interrupt request line, the CPU performs a state-save, and transfers control over to the proper interrupt handler, which in turn runs the scheduler.
- The scheduler does a state-restore of a different process before resetting the timer and issuing the return-from-interrupt instruction.
- A similar example involves the paging system for virtual memory - A page fault causes an interrupt, which in turn issues an I/O request and a context switch as described above, moving the interrupted process into the wait queue and selecting a different process to run. When the I/O request has completed ( i.e. when the requested page has been loaded up into physical memory ), then the device interrupts, and the interrupt handler moves the process from the wait queue into the ready queue, ( or depending on scheduling algorithms and policies, may go ahead and context switch it back onto the CPU. )
- System calls are implemented via software interrupts, a.k.a. traps. When a ( library ) program needs work performed in kernel mode, it sets command information and possibly data addresses in certain registers, and then raises a software interrupt. ( E.g. 21 hex in DOS. ) The system does a state save and then calls on the proper interrupt handler to process the request in kernel mode. Software interrupts generally have low priority, as they are not as urgent as devices with limited buffering space.
- Interrupts are also used to control kernel operations, and to schedule activities for optimal performance. For example, the completion of a disk read operation involves twointerrupts:
- A high-priority interrupt acknowledges the device completion, and issues the next disk request so that the hardware does not sit idle.
- A lower-priority interrupt transfers the data from the kernel memory space to the user space, and then transfers the process from the waiting queue to the ready queue.
- The Solaris OS uses a multi-threaded kernel and priority threads to assign different threads to different interrupt handlers. This allows for the "simultaneous" handling of multiple interrupts, and the assurance that high-priority interrupts will take precedence over low-priority ones and over user processes.
13.2.3 Direct Memory Access
- For devices that transfer large quantities of data ( such as disk controllers ), it is wasteful to tie up the CPU transferring data in and out of registers one byte at a time.
- Instead this work can be off-loaded to a special processor, known as the Direct Memory Access, DMA, Controller.
- The host issues a command to the DMA controller, indicating the location where the data is located, the location where the data is to be transferred to, and the number of bytes of data to transfer. The DMA controller handles the data transfer, and then interrupts the CPU when the transfer is complete.
- A simple DMA controller is a standard component in modern PCs, and many bus-mastering I/O cards contain their own DMA hardware.
- Handshaking between DMA controllers and their devices is accomplished through two wires called the DMA-request and DMA-acknowledge wires.
- While the DMA transfer is going on the CPU does not have access to the PCI bus ( including main memory ), but it does have access to its internal registers and primary and secondary caches.
- DMA can be done in terms of either physical addresses or virtual addresses that are mapped to physical addresses. The latter approach is known as Direct Virtual Memory Access, DVMA, and allows direct data transfer from one memory-mapped device to another without using the main memory chips.
- Direct DMA access by user processes can speed up operations, but is generally forbidden by modern systems for security and protection reasons. ( I.e. DMA is a kernel-mode operation. )
- Figure 13.5 below illustrates the DMA process.
Figure 13.5 - Steps in a DMA transfer.13.2.4 I/O Hardware Summary