3.6 Communication in Client-Server Systems
3.6.1 Sockets
- A socket is an endpoint for communication.
- Two processes communicating over a network often use a pair of connected sockets as a communication channel. Software that is designed for client-server operation may also use sockets for communication between two processes running on the same computer - For example the UI for a database program may communicate with the back-end database manager using sockets. ( If the program were developed this way from the beginning, it makes it very easy to port it from a single-computer system to a networked application. )
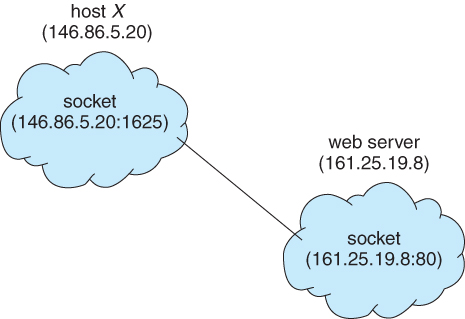
- A socket is identified by an IP address concatenated with a port number, e.g. 200.100.50.5:80.
Figure 3.20 - Communication using sockets
- Port numbers below 1024 are considered to be well-known, and are generally reserved for common Internet services. For example, telnet servers listen to port 23, ftp servers to port 21, and web servers to port 80.
- General purpose user sockets are assigned unused ports over 1024 by the operating system in response to system calls such as socket( ) or soctkepair( ).
- Communication channels via sockets may be of one of two major forms:
- Connection-oriented ( TCP, Transmission Control Protocol ) connections emulate a telephone connection. All packets sent down the connection are guaranteed to arrive in good condition at the other end, and to be delivered to the receiving process in the order in which they were sent. The TCP layer of the network protocol takes steps to verify all packets sent, re-send packets if necessary, and arrange the received packets in the proper order before delivering them to the receiving process. There is a certain amount of overhead involved in this procedure, and if one packet is missing or delayed, then any packets which follow will have to wait until the errant packet is delivered before they can continue their journey.
- Connectionless ( UDP, User Datagram Protocol ) emulate individual telegrams. There is no guarantee that any particular packet will get through undamaged ( or at all ), and no guarantee that the packets will get delivered in any particular order. There may even be duplicate packets delivered, depending on how the intermediary connections are configured. UDP transmissions are much faster than TCP, but applications must implement their own error checking and recovery procedures.
- Sockets are considered a low-level communications channel, and processes may often choose to use something at a higher level, such as those covered in the next two sections.
- Figure 3.19 and 3.20 illustrate a client-server system for determining the current date using sockets in Java.
Figure 3.21 and Figure 3.223.6.2 Remote Procedure Calls, RPC
- The general concept of RPC is to make procedure calls similarly to calling on ordinary local procedures, except the procedure being called lies on a remote machine.
- Implementation involves stubs on either end of the connection.
- The local process calls on the stub, much as it would call upon a local procedure.
- The RPC system packages up ( marshals ) the parameters to the procedure call, and transmits them to the remote system.
- On the remote side, the RPC daemon accepts the parameters and calls upon the appropriate remote procedure to perform the requested work.
- Any results to be returned are then packaged up and sent back by the RPC system to the local system, which then unpackages them and returns the results to the local calling procedure.
- One potential difficulty is the formatting of data on local versus remote systems. ( e.g. big-endian versus little-endian. ) The resolution of this problem generally involves an agreed-upon intermediary format, such as XDR ( external data representation. )
- Another issue is identifying which procedure on the remote system a particular RPC is destined for.
- Remote procedures are identified by ports, though not the same ports as the socket ports described earlier.
- One solution is for the calling procedure to know the port number they wish to communicate with on the remote system. This is problematic, as the port number would be compiled into the code, and it makes it break down if the remote system changes their port numbers.
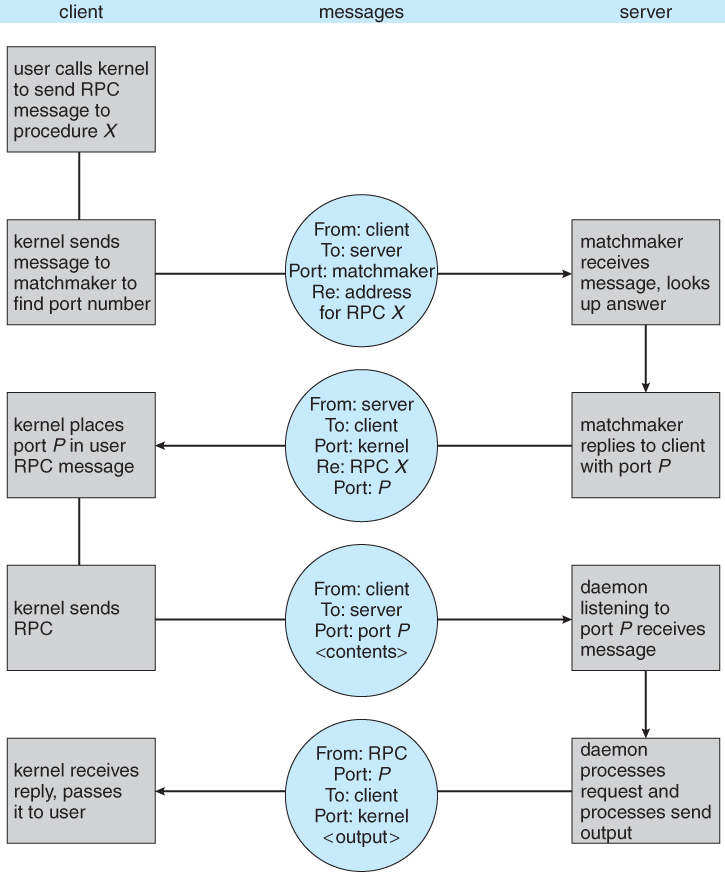
- More commonly a matchmaker process is employed, which acts like a telephone directory service. The local process must first contact the matchmaker on the remote system ( at a well-known port number ), which looks up the desired port number and returns it. The local process can then use that information to contact the desired remote procedure. This operation involves an extra step, but is much more flexible. An example of the matchmaker process is illustrated in Figure 3.21 below.
- One common example of a system based on RPC calls is a networked file system. Messages are passed to read, write, delete, rename, or check status, as might be made for ordinary local disk access requests.
Figure 3.23 - Execution of a remote procedure call ( RPC ).3.6.3 Pipes
- Pipes are one of the earliest and simplest channels of communications between ( UNIX ) processes.
- There are four key considerations in implementing pipes:
- Unidirectional or Bidirectional communication?
- Is bidirectional communication half-duplex or full-duplex?
- Must a relationship such as parent-child exist between the processes?
- Can pipes communicate over a network, or only on the same machine?
- The following sections examine these issues on UNIX and Windows
3.6.3.1 Ordinary Pipes
- Ordinary pipes are uni-directional, with a reading end and a writing end. ( If bidirectional communications are needed, then a second pipe is required. )
- In UNIX ordinary pipes are created with the system call "int pipe( int fd [ ] )".
- The return value is 0 on success, -1 if an error occurs.
- The int array must be allocated before the call, and the values are filled in by the pipe system call:
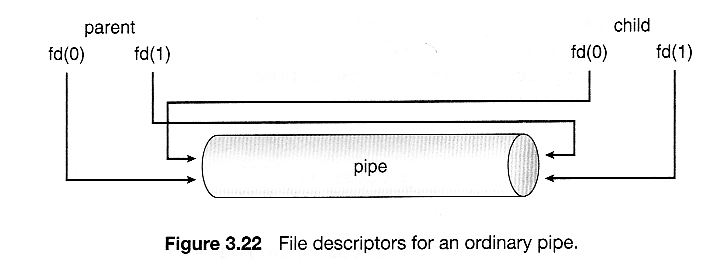
- fd[ 0 ] is filled in with a file descriptor for the reading end of the pipe
- fd[ 1 ] is filled in with a file descriptor for the writing end of the pipe
- UNIX pipes are accessible as files, using standard read( ) and write( ) system calls.
- Ordinary pipes are only accessible within the process that created them.
- Typically a parent creates the pipe before forking off a child.
- When the child inherits open files from its parent, including the pipe file(s), a channel of communication is established.
- Each process ( parent and child ) should first close the ends of the pipe that they are not using. For example, if the parent is writing to the pipe and the child is reading, then the parent should close the reading end of its pipe after the fork and the child should close the writing end.
- Figure 3.22 shows an ordinary pipe in UNIX, and Figure 3.23 shows code in which it is used.
Figure 3.24
Figure 3.25 and Figure 3.26
- Ordinary pipes in Windows are very similar
- Windows terms them anonymous pipes
- They are still limited to parent-child relationships.
- They are read from and written to as files.
- They are created with CreatePipe( ) function, which takes additional arguments.
- In Windows it is necessary to specify what resources a child inherits, such as pipes.
Figure 3.27 and Figure 3.28
Figure 3.293.6.3.2 Named Pipes
- Named pipes support bidirectional communication, communication between non parent-child related processes, and persistence after the process which created them exits. Multiple processes can also share a named pipe, typically one reader and multiple writers.
- In UNIX, named pipes are termed fifos, and appear as ordinary files in the file system.
- ( Recognizable by a "p" as the first character of a long listing, e.g. /dev/initctl )
- Created with mkfifo( ) and manipulated with read( ), write( ), open( ), close( ), etc.
- UNIX named pipes are bidirectional, but half-duplex, so two pipes are still typically used for bidirectional communications.
- UNIX named pipes still require that all processes be running on the same machine. Otherwise sockets are used.
- Windows named pipes provide richer communications.
- Full-duplex is supported.
- Processes may reside on the same or different machines
- Created and manipulated using CreateNamedPipe( ), ConnectNamedPipe( ), ReadFile( ),and WriteFile( ).
Race Conditions ( Not from the book )
Any time there are two or more processes or threads operating concurrently, there is potential for a particularly difficult class of problems known as race conditions. The identifying characteristic of race conditions is that the performance varies depending on which process or thread executes their instructions before the other one, and this becomes a problem when the program runs correctly in some instances and incorrectly in others. Race conditions are notoriously difficult to debug, because they are unpredictable, unrepeatable, and may not exhibit themselves for years.
Here is an example involving a server and a client communicating via sockets:
1. First the server writes a greeting message to the client via the socket:
const int BUFFLENGTH = 100; char buffer[ BUFFLENGTH ]; sprintf( buffer, "Hello Client %d!", i ); write( clientSockets[ i ], buffer, strlen( buffer ) + 1 );2. The client then reads the greeting into its own buffer. The client does not know for sure how long the message is, so it allocates a buffer bigger than it needs to be. The following will read all available characters in the socket, up to a maximum of BUFFLENGTH characters:
const int BUFFLENGTH = 100; char buffer[ BUFFLENGTH ]; read( mysocket, buffer, BUFFLENGTH ); cout << "Client received: " << buffer << "\n";3. Now the server prepares a packet of work and writes that to the socket:
write( clientSockets[ i ], & wPacket, sizeof( wPacket ) );4. And finally the client reads in the work packet and processes it:
read( mysocket, & wPacket, sizeof( wPacket ) );The Problem: The problem arises if the server executes step 3 before the client has had a chance to execute step 2, which can easily happen depending on process scheduling. In this case, when the client finally gets around to executing step 2, it will read in not only the original greeting, but also the first part of the work packet. And just to make things harder to figure out, the cout << statement in step 2 will only print out the greeting message, since there is a null byte at the end of the greeting. This actually isn't even a problem at this point, but then later when the client executes step 4, it does not accurately read in the work packet because part of it has already been read into the buffer in step 2.
Solution I: The easiest solution is to have the server write the entire buffer in step 1, rather than just the part filled with the greeting, as:
write( clientSockets[ i ], buffer, BUFFLENGTH );Unfortunately this solution has two problems: (1) It wastes bandwidth and time by writing more than is needed, and more importantly, (2) It leaves the code open to future problems if the BUFFLENGTH is not the same in the client and in the server.
Solution II: A better approach for handling variable-length strings is to first write the length of the string, followed by the string itself as a separate write. Under this solution the server code changes to:
sprintf( buffer, "Hello Client %d!", i ); int length = strlen( buffer ) + 1; write( clientSockets[ i ], &length, sizeof( int ) ); write( clientSockets[ i ], buffer, length );
and the client code changes to:int length; if( read( mysocket, &length, sizeof( int ) ) != sizeof( int ) ) { perror( "client read error: " ); exit( -1 ); } if( length < 1 || length > BUFFLENGTH ) { cerr << "Client read invalid length = " << length << endl; exit( -1 ); } if( read( mysocket, buffer, length ) != length ) { perror( "client read error: " ); exit( -1 ); } cout << "Client received: " << buffer << "\n";Note that the above solution also checks the return value from the read system call, to verify that the number of characters read is equal to the number expected. ( Some of those checks were actually in the original code, but were omitted from the notes for clarity. The real code also uses select( ) before reading, to verify that there are characters present to read and to delay if not. )
Note also that this problem could not be ( easily ) solved using the synchronization tools covered in chapter 6, because the problem is not really one of two processes accessing the same data at the same time.